Private RAG Systems Without External APIs
Summary
Mid-sized teams can build secure, self-hosted AI assistants with open-source models, vector stores, and RAG — without routing proprietary data through third-party APIs.
Generative AI content is everywhere; execution is rarer. Mid-sized companies often feel overwhelmed by the volume of information available. The reality is that with the right approach, even small teams can develop powerful AI tools using their own data — without relying solely on OpenAI or external APIs.
One particularly practical use case is a private, self-hosted chatbot or web/mobile interface powered by Retrieval-Augmented Generation (RAG).
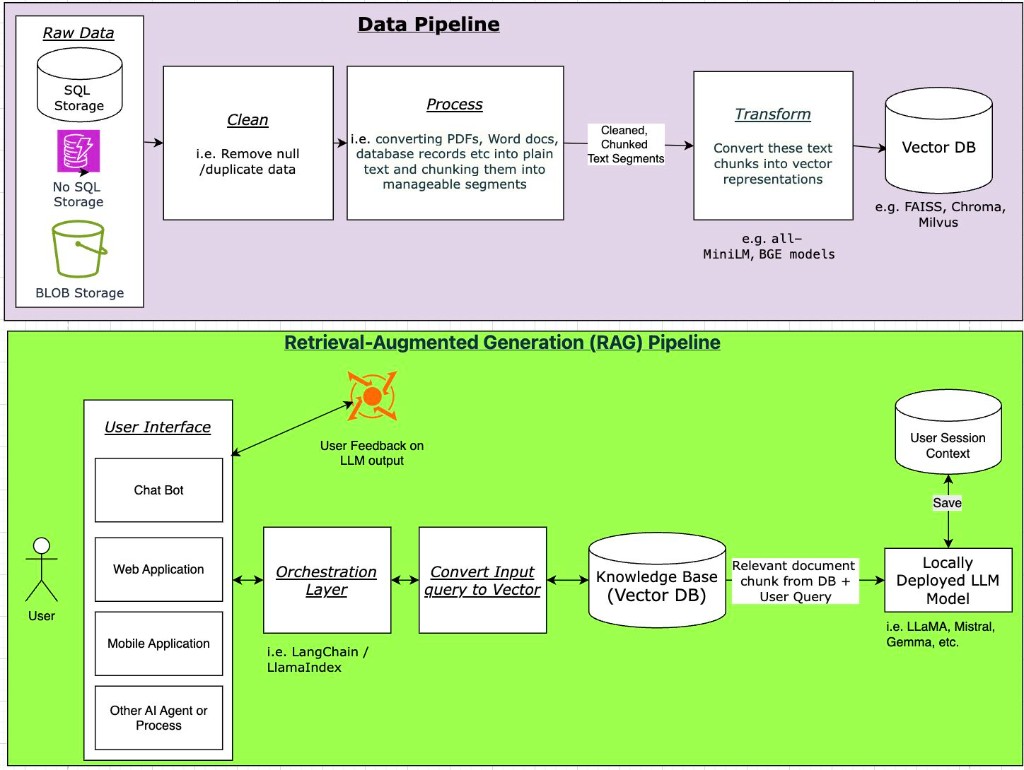
The architecture in two pipelines
The data pipeline ingests raw data from SQL, NoSQL, and blob storage, cleans nulls and duplicates, processes documents into text chunks, transforms chunks into vector embeddings (using models like all-MiniLM or BGE), and stores them in a vector database (FAISS, Chroma, or Milvus).
The RAG pipeline handles user queries through an orchestration layer (LangChain or LlamaIndex), converts queries to vectors, retrieves relevant document chunks from the knowledge base, and sends context plus the user query to a locally deployed LLM (LLaMA, Mistral, or Gemma). Session context and user feedback close the loop.
Why build in-house? Open-source models plus FAISS, ChromaDB, LangChain, or LlamaIndex make secure AI assistants achievable for motivated teams. Designing an LLM system from scratch is simpler than it may seem.
The strategic question for engineering leaders is not "should we use AI?" — it is whether to rent intelligence through APIs or own the pipeline when data sensitivity, cost at scale, and customization matter.
Related reading
How Software Engineering Teams Should Look in the AI Era
The traditional model repeats the same roles across siloed domain teams. The AI-era model connects specialized squads through an Efficiency Team building shared MCPs, RAG pipelines, agents, and agentic workflows.
Embeddings and Vector Databases: The Search Layer Behind Real AI Applications
Embeddings convert meaning into vectors; vector databases make those vectors searchable. Together they form the retrieval foundation behind RAG, semantic search, and enterprise AI assistants.
RAG vs Graph RAG vs Agentic RAG: How to Choose the Right Architecture
Standard RAG, Graph RAG, and Agentic RAG all connect LLMs to private data — but they solve different problems. Match the architecture to the question: retrieval, relationships, or reasoning.